
Crack ML System Design Interviews Like a Pro - Part 1
Real Stories, Real Strategies: An Interviewer's Guide to what Actually Works

Hey, Rahul here! 👋 Each week, I publish long-form ML+AI posts covering ML, AI, and System design for MLwhiz. Paid subscribers also get how-to guides with full code walkthroughs. I publish occasional extra articles. If you’d like to become a paid subscriber, here’s a button for that:

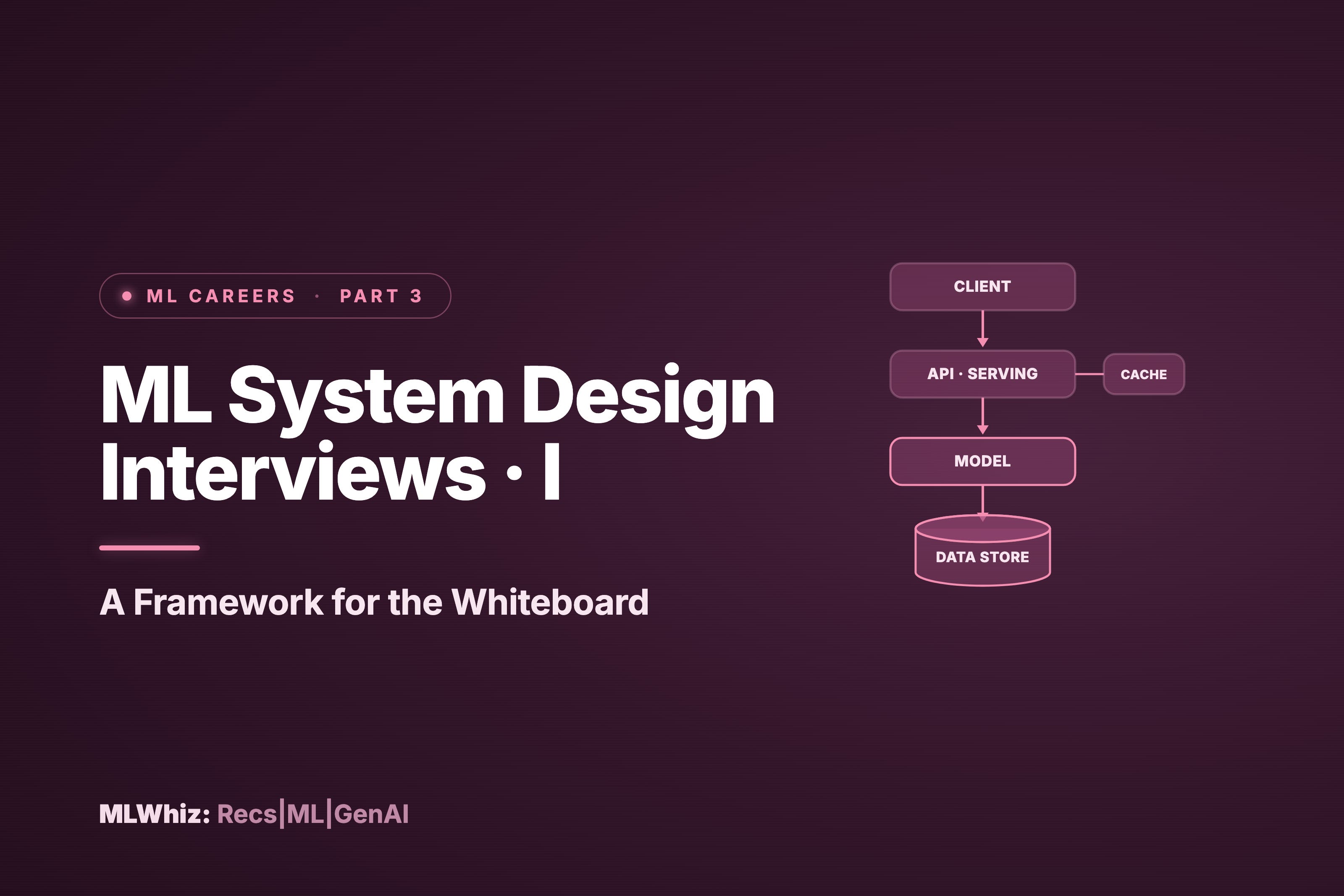
Let me share something that's been on my mind lately – ML system design interviews. You know what fascinates me? These interviews aren't just technical assessments; they're a test of how well you can structure and communicate complex ideas under pressure. I've been on both sides of the table, and I've noticed that even brilliant engineers sometimes struggle not because they lack knowledge, but because they haven't mastered the art of presenting their thoughts systematically. So, I thought I'd break down my approach to tackling these interviews, sharing real experiences and lessons learned along the way. Let's dive in!
Picture this: you walk into the interview room (or join the Zoom call these days), and the interviewer says, “Design a recommendation system for Netflix.” Where do you even start? This is where having a solid framework saves you. So here is one design framework I propose:

Requirements Gathering
First things first – and I can’t stress this enough – don’t jump straight into solutions! I’ve seen so many candidates eager to show off their ML knowledge that they start talking about matrix factorization or deep learning before understanding what they’re building.
Here’s what you should do instead. Take a deep breath and start with questions. Let me share a real interview experience. I was taking an ML design interview just the other day and I began with an ML design question about search. And the TC immediately jumped into the modeling part. I had to bring them back to the question at hand and make them structure their interview. At that time, I knew then that they were not suitable for a senior role. I know, it’s pretty harsh to judge someone like that, but you can only do so much in a 1-hour interview. So, better to follow a structure. Here is a structure I recommend:
A. Scope Clarification: Start with the basics:
“Are we building this for all Netflix users or a specific region?”
“Should we focus on movie recommendations, TV shows, or both?”
“What’s our main goal – increasing watch time, user engagement, or something else?”
“What type of queries can users do over in a search system? Is it title queries, category queries, or both? Or are they complete queries or partial queries?”
Here’s a pro tip that saved me multiple times: write these points down on the whiteboard (or shared document for virtual interviews). It shows structured thinking and gives you something to refer back to when you need to justify your decisions later.
B. Functional Requirements: Get specific about what the system needs to do:
Input: “What data do we have about users? Just ratings, or do we also have watch history, partial views, etc.?”
Output: “How many recommendations should we show? Do we need to explain why we’re recommending each item?”
Features: “Do we need real-time updates based on what the user just watched?”
C. Non-functional Requirements: This is where you show you think like an ML engineer, not just a data scientist:
Scale: “How many users are we serving? Netflix has over 200 million subscribers – that’s a lot of recommendations to generate!”
Latency: “How fast do recommendations need to be? For the homepage, we probably want recommendations ready before the user logs in.”
Availability: “What happens if our recommendation service goes down? Do we need a fallback?”
