
HSTU From Scratch in PyTorch - A complete Walkthrough
RecSys for MLEs Part 9d: data pipeline, three sub-layers, retrieval + rating loss, and benchmarking against rectools' HSTU on MovieLens-1M

Hey, Rahul here! 👋 Each week, I publish long-form ML+AI posts covering ML, AI, and System design for MLwhiz. Paid subscribers also get how-to guides with full code walkthroughs. I publish occasional extra articles. If you’d like to become a paid subscriber, here’s a button for that:

This is Part 9d of the RecSys for MLEs series. Part 9c explained why HSTU works: the softmax-to-SiLU switch that preserves engagement intensity, relative attention bias that gives the model a sense of time, and M-FALCON for cheap candidate scoring. This post is the hands-on follow-up. We’re going to train an HSTU from scratch, on the MovieLens-1M dataset, and benchmark it against the rectools library’s reference HSTU implementation, so you have a real number to compare against.
Last week, I published the conceptual deep dive on HSTU. Within 24 hours, the most common question in my replies was the same: “OK, but how do I actually train one?”
Fair. So today we build it from scratch — the fused (item, action) input layer, all three HSTU sub-layers, the multi-task retrieval + rating heads, and the M-FALCON inference cache. We’ll train it on MovieLens-1M, then benchmark head-to-head against rectools’ reference HSTU implementation, so you have a real number to compare against.
We’ll use PyTorch 2.x on a single GPU (a free Colab T4 works fine). I’m intentionally keeping the model small (D=64, 2 layers) so it trains in few hours on free hardware. And to make sure I wasn’t fooling myself with vanity numbers, I trained the rectools library’s HSTU on the same data and split, then ran my from-scratch model with a similar training config. That way, if my numbers come out worse, I know exactly where to look.
Here’s what we’ll cover:
The dataset: how MovieLens ratings map to the (item, action, time) triples HSTU consumes
The fused input layer: item embedding + action embedding + fusion MLP
The HSTU block: all three sub-layers as a single PyTorch module — SiLU attention, RAB, gated transformation
Multi-task heads: retrieval (sampled softmax with cosine similarity + temperature) and rating prediction
Results: HR@10 and NDCG@10 against rectools HSTU and SASRec, plus the SiLU vs softmax ablation
Example predictions: what the model actually recommends for specific MovieLens users
Retrieval and ranking demos: brute-force, FAISS, and ranking by retrieval score + predicted rating
M-FALCON inference: the K/V caching trick that makes serving feasible
Notebooks to read alongside the post:
📓 hstu-from-scratch-ml1m-v2.ipynb — the from-scratch HSTU we build in this post
📓 rectools-ml1m.ipynb — the rectools HSTU + SASRec baseline notebook for the comparison numbers
1. The dataset: MovieLens-1M ratings as (item, action, time) triples

One of the most basic but important questions that we need to answer is how the data is structured. We’re using MovieLens-1M from GroupLens which contains ~1M ratings across 6,040 users and 3,706 movies.
Each row is (user, movie, rating, timestamp) where rating is 1-5 stars. SASRec would treat every rating as one positive interaction. HSTU’s input can be richer — it can fuse the action type alongside the item ID — so I want to give the model the rating sentiment, not just the fact that the user watched the movie. This is how I’m incorporating an action signal in this model. Honestly, every setup can have a different action vocabulary — add-to-cart vs. purchase on an e-commerce store, click vs. like vs. share on a feed, watch-25% vs. watch-90% vs. skip on a video platform. The point I want to make here is that HSTU lets you encode whichever signal actually matters for your domain, not just “the user clicked this item.”
For our case, we create three behavioral signals, derived from the rating value:
POSITIVE (rating ≥ 4): the user liked the movie
NEUTRAL (rating = 3): the user was indifferent
NEGATIVE (rating < 3): the user disliked the movie
The actual rating value (1-5) is kept separately as the label for the rating-prediction head.
import pandas as pd
import numpy as np
ratings = pd.read_csv(”ml-1m/ratings.dat”, sep=”::”, header=None,
names=[”user”, “item”, “rating”, “ts”], engine=”python”)
def rating_to_action(r):
if r >= 4: return “POSITIVE”
if r == 3: return “NEUTRAL”
return “NEGATIVE”
events = ratings.copy()
events[”action”] = events[”rating”].apply(rating_to_action)
events[”value”] = events[”rating”].astype(np.float32)
print(events.action.value_counts())
# POSITIVE 575281
# NEUTRAL 261197
# NEGATIVE 163731Train/test split: leave-one-out. For each user, the last interaction goes to test, and everything before that goes to training. During training, the last item of the training sequence is held out as the validation target.
def split_seq(seq, max_len=200):
n = len(seq[”items”])
if n < 3: return None
history_slice = slice(max(0, n - 1 - max_len), n - 1)
history = {k: seq[k][history_slice].tolist() for k in seq}
test_target = (
int(seq[”items”][n - 1]),
int(seq[”actions”][n - 1]),
int(seq[”times”][n - 1]),
float(seq[”values”][n - 1]),
)
return history, test_target
splits = [s for s in (split_seq(seq) for seq in sequences) if s is not None]
# Train/test sequences: 6,040
max_len=200 is the cap. With an average length of 165, most users will fit. Long-tail users get truncated to their most recent 200 events.
2. The fused input: item embedding + action embedding + fusion MLP
 and action_emb (D) concatenate to (B, T, 2D), pass through Linear → SiLU → Linear MLP, output a single fused vector (B, T, D)")
Here’s the actual code.
import torch
import torch.nn as nn
import torch.nn.functional as F
class FusedInputEmbedding(nn.Module):
“”“Item embedding + action embedding, fused with an MLP into a single D-dim vector.”“”
def __init__(self, num_items, num_actions, dim):
super().__init__()
self.item_emb = nn.Embedding(num_items + 1, dim, padding_idx=0)
self.action_emb = nn.Embedding(num_actions + 1, dim, padding_idx=0)
self.fuse = nn.Sequential(
nn.Linear(2 * dim, dim),
nn.SiLU(),
nn.Linear(dim, dim),
)
def forward(self, item_ids, action_ids):
i = self.item_emb(item_ids) # (B, T, D)
a = self.action_emb(action_ids) # (B, T, D)
return self.fuse(torch.cat([i, a], dim=-1)) # (B, T, D)
What’s happening here is that each item ID looks up a D-dim vector in item_emb (the “what is this item” signal) table, and each action ID looks up another D-dim vector in action_emb (the “how did the user engage with it” signal).
The forward pass then concatenates them into a 2D-dim vector per token, then the fuse MLP projects back to D dims.
The MLP matters. It’s what lets the model learn that “watched Toy Story with rating 5” represents something different from “watched Toy Story with rating 1”. A simple sum or concatenation wouldn’t give the model the capacity to learn that interaction.
3. The HSTU block in PyTorch
Now, it is time to write the actual HSTU block. If you want to refresh on what each piece does, Part 9c walks through the three sub-layers conceptually. Here I’ll just translate that directly into code.
First, the relative attention bias (RAB) module. Two learnable tables: one for relative position offset, one for log-spaced time buckets.
class RelativeAttentionBias(nn.Module):
“”“Learnable position + time biases, added to QK^T before SiLU.”“”
TIME_BUCKETS = [
(0, 3600), # 0-1 hour
(3600, 86400), # 1-24 hours
(86400, 86400 * 7), # 1-7 days
(86400 * 7, 86400 * 30), # 7-30 days
(86400 * 30, float(”inf”)), # 30+ days
]
def __init__(self, max_seq_len):
super().__init__()
self.max_seq_len = max_seq_len
self.pos_bias = nn.Embedding(2 * max_seq_len - 1, 1)
self.time_bias = nn.Embedding(len(self.TIME_BUCKETS), 1)
nn.init.zeros_(self.pos_bias.weight)
nn.init.zeros_(self.time_bias.weight)
def _bucket(self, time_deltas):
out = torch.zeros_like(time_deltas, dtype=torch.long)
for k, (lo, hi) in enumerate(self.TIME_BUCKETS):
mask = (time_deltas >= lo) & (time_deltas < hi)
out = torch.where(mask, torch.full_like(out, k), out)
return out
def forward(self, times):
B, T = times.shape
idx = torch.arange(T, device=times.device)
rel_pos = (idx.view(T, 1) - idx.view(1, T)) + (self.max_seq_len - 1)
pos_b = self.pos_bias(rel_pos).squeeze(-1)
time_deltas = (times.unsqueeze(2) - times.unsqueeze(1)).abs()
time_b = self.time_bias(self._bucket(time_deltas)).squeeze(-1)
return pos_b.unsqueeze(0) + time_b
Initialize both bias tables to zeros. That way, the first forward pass behaves like a vanilla attention block, and the time/position biases learn from gradient flow.
Now the HSTU block itself:
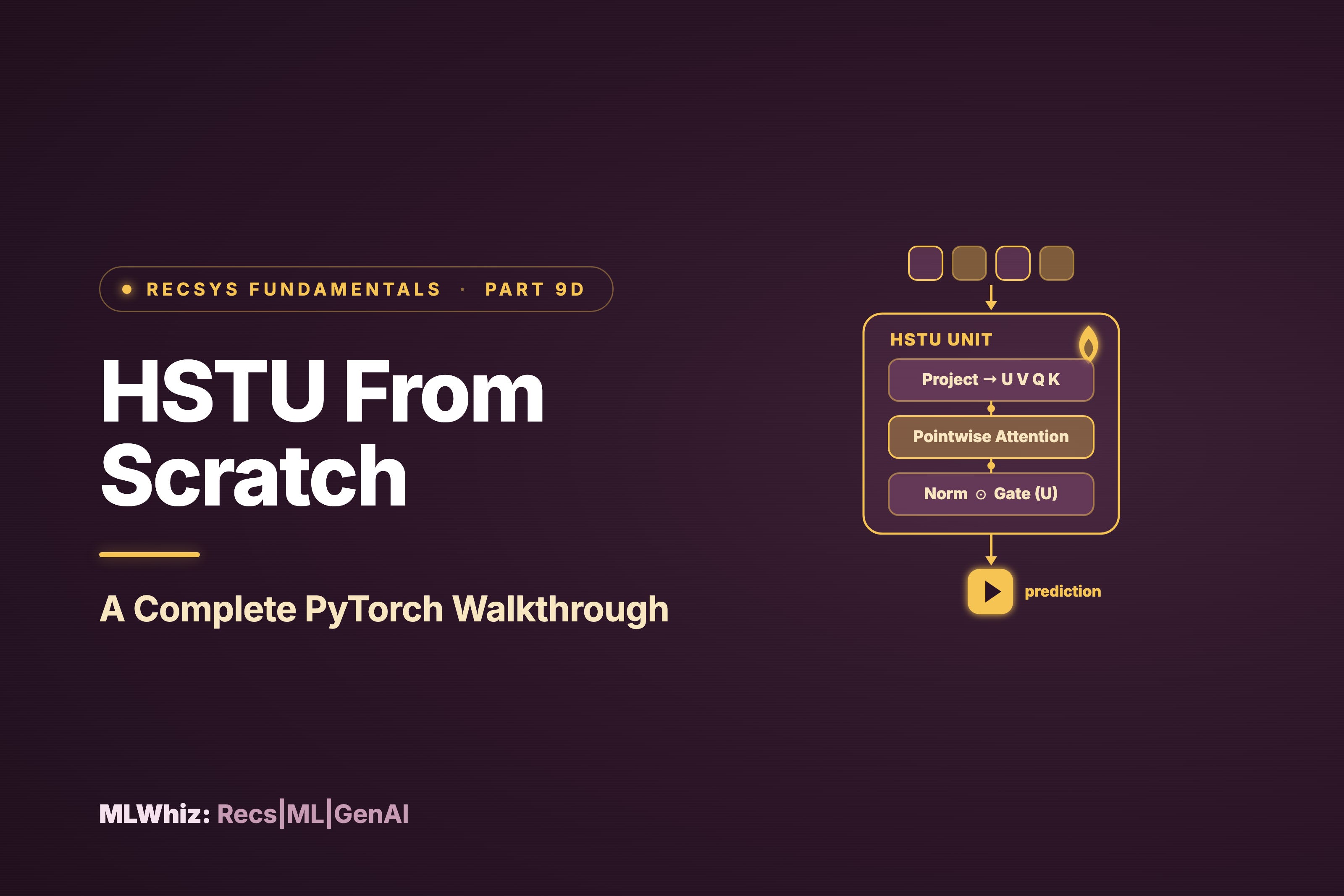
class HSTUBlock(nn.Module):
def __init__(self, dim, max_seq_len, dropout=0.2):
super().__init__()
self.linear_in = nn.Linear(dim, 4 * dim)
self.rab = RelativeAttentionBias(max_seq_len)
self.norm = nn.LayerNorm(dim)
self.linear_out = nn.Linear(dim, dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x, times, attn_mask):
B, T, D = x.shape
# --- Sub-layer 1: pointwise projection ---
proj = F.silu(self.linear_in(x))
K, Q, V, U = proj.chunk(4, dim=-1)
# --- Sub-layer 2: spatial aggregation (SiLU attention + RAB + causal/pad mask) ---
scores = torch.matmul(Q, K.transpose(-2, -1)) + self.rab(times)
causal = torch.tril(torch.ones(T, T, device=x.device))
scores = scores * causal
pad_mask = attn_mask.unsqueeze(1).float()
scores = scores * pad_mask
activated = F.silu(scores) # NOT softmax — pointwise SiLU
attn_out = torch.matmul(activated, V) / T # 1/T normalization
# --- Sub-layer 3: gated transformation + residual ---
gated = self.norm(attn_out) * U
output = self.dropout(self.linear_out(gated))
return output + x
Stacking blocks is one line:
class HSTUEncoder(nn.Module):
def __init__(self, num_items, num_actions, dim, num_layers, max_seq_len, dropout=0.2):
super().__init__()
self.embed = FusedInputEmbedding(num_items, num_actions, dim)
self.blocks = nn.ModuleList([
HSTUBlock(dim, max_seq_len, dropout=dropout) for _ in range(num_layers)
])
def forward(self, item_ids, action_ids, times, attn_mask):
x = self.embed(item_ids, action_ids)
for block in self.blocks:
x = block(x, times, attn_mask)
return x
That’s the encoder.
The rest of this post covers the multi-task heads (retrieval + rating), the full results table comparing our from-scratch HSTU to rectools HSTU and SASRec, the SiLU vs softmax ablation, the learned time-bias curve, M-FALCON inference benchmark (210× speedup), and a production field guide.
