From Random IDs to Semantic IDs: Building a Generative Recommender from Scratch
RecSys Series Part 9b: Implementing RQVAE and TIGER on the Steam Games dataset with Qwen embeddings

Hey, Rahul here! 👋 Each week, I publish long-form ML+AI posts covering ML, AI, and System design for MLwhiz. Paid subscribers also get how-to guides with full code walkthroughs. I publish occasional extra articles. If you’d like to become a paid subscriber, here’s a button for that:


At the end of Part 1, I left you with a question: What if items had semantic identifiers that captured their content?
That question sounds innocent enough, but it’s actually the hinge point for the entire generative recommender revolution we are going to be talking about in this post. And it is very interesting to say the least.
So, we built GRU4Rec and SASRec on the Steam Games dataset in our previous post. But both those models treat items as arbitrary integers. The model sees “Item 4,271 → Item 8,903 → Item 2,156” and learns some sort of statistical patterns between these numbers.
The thing we need to note is that everything about what these games actually are — their genre, their developer, their visual style, the reason a player moves from one to the next — lives entirely outside the model. That is a pretty big opportunity to work on.
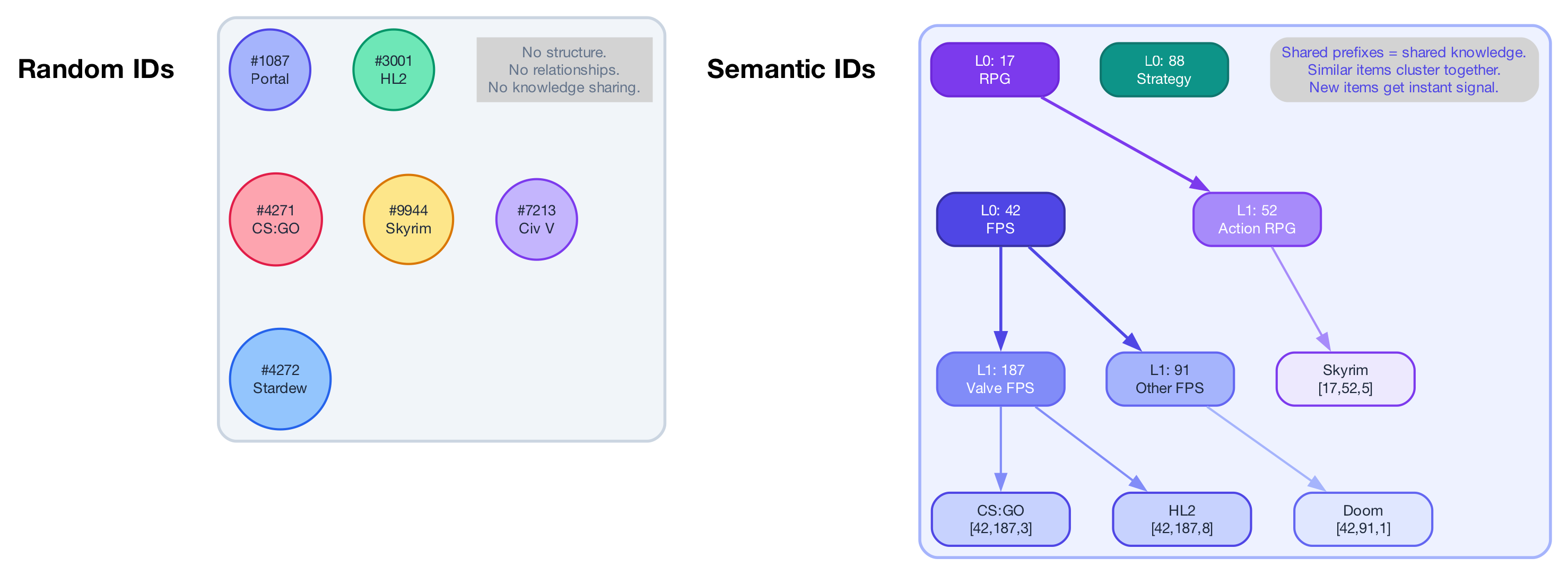
Now imagine if every item carried an ID that meant something. Similar games naturally share ID prefixes. A brand-new title gets a meaningful ID the moment it’s published — before anyone plays it. The recommender can reason about games it’s never seen just from their ID, just like a human would by seeing a game’s description or title.
That’s Semantic IDs.
And these semantic IDs unlock something bigger →instead of scoring candidates from a retrieved shortlist(which is how SASRec and GRU4Rec work), a model can now generate the next item token by token, the way GPT generates words.
In this post, we will create a complete pipeline to do exactly that on the same Steam dataset, every game compressed into meaningful tokens using Residual Quantized VAE, and a generative recommender(TIGER) trained from scratch.
Let’s dive in!
1. The Problem with Random Item IDs
Just think about how SASRec works for a second - A user plays [Counter-Strike, Portal, Half-Life 2]. The model looks up the embedding for each game, runs self-attention, and predicts the next game. So far, so good.
But what does the model actually know about Counter-Strike? Nothing. It’s just item ID 4,271. The model has no idea it’s a first-person shooter made by Valve in 2004.
This creates three problems that compound in production:
No knowledge sharing. If 10,000 users play Counter-Strike → Team Fortress 2, the model learns that specific transition. But it learns nothing about why they’re related. A new Valve FPS arrives tomorrow, and the model has zero signal for it — even though any human could tell you “people who like Counter-Strike would probably like this.”
Cold-start is brutal. New items have brand-new IDs with randomly initialized embeddings. As I covered in my post on the cold-start problem, this means they need thousands of interactions before the model can meaningfully recommend them. In fast-moving catalogs — think news, short videos, new game releases — items can go stale before the model even learns to recommend them.
No generalization. The model memorizes specific ID→ID transitions. It can’t reason about categories of items, properties of items, or relationships between items.
And that’s where semantic IDs could help us.
2. Semantic IDs: Making Item IDs mean Something
Ok, so now we understand why Semantic IDs might be beneficial, let’s see how they are made. The idea behind Semantic IDs was introduced in TIGER (Transformer Index for Generative Recommenders) at NeurIPS 2023, and it completely changed how we think about item representation in recommender systems.
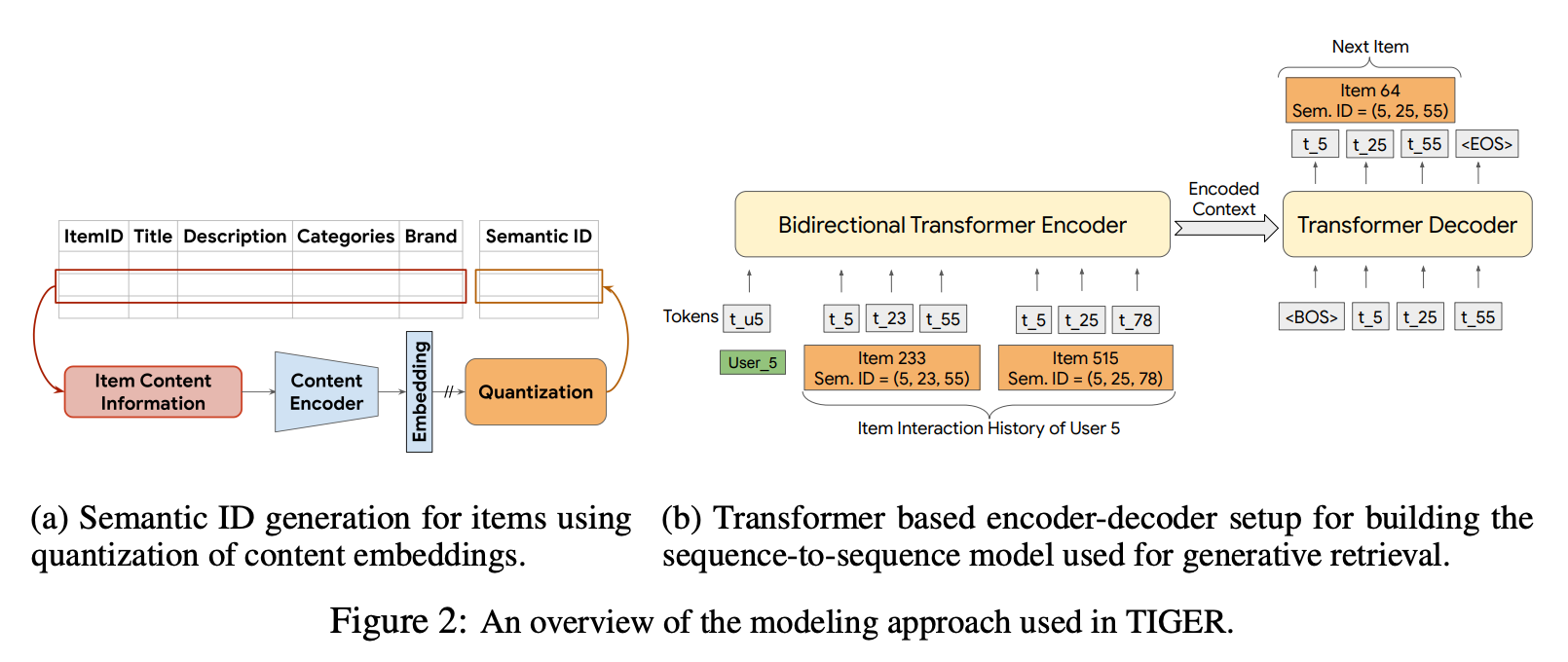
The pipeline works in three steps. Here’s what happens to a single game:

In step 1, we start by getting a content-based embedding of an item using a powerful text encoder.
Once we have that, we run the RQVAE algorithm in step 2 to generate Semantic IDs of items. (Don’t worry, we will talk about this in this post. For now, just understand that it gives you some sort of discrete token-based vector given your item embeddings)
In Step 3, we generate the next item’s Semantic ID token by token, the same way GPT writes one word at a time. It’s not scoring a fixed list; it’s constructing an answer.
Now think about what this structure gives you. Counter-Strike and Half-Life might both get the prefix [42, 187, ...] because they’re both Valve FPS games. A brand-new Valve FPS that launched this morning might then be assigned a similar prefix based purely on its content — and the model already knows what to do with items that start with [42, 187, ...], even though it’s never seen a single player interact with this game.
Remember how in the cold start post I wrote about how new items have nothing but their metadata to work with? With Semantic IDs, the metadata becomes their ID. The model doesn’t need thousands of interactions to figure out what a new game is — it already knows, just from reading the ID.
And notice what else changed: we replaced the entire retrieve→rank→rerank pipeline with a single model that generates recommendations directly. At inference time, the decoder uses beam search: instead of greedily committing to one token at each level and hoping for the best, it keeps the top B candidates at each step and extends them all in parallel. You end up with a ranked list of complete Semantic IDs, each mapping to a real item. That means you don’t have to worry about maintaining an ANN index, a candidate retrieval stage, and a separate ranker stage. You can get all of this from a single model.
Now, the magic of this pipeline lives entirely in Step 2 — the RQVAE. That is how we create these semantic IDs. And if the quantization is bad, the Semantic IDs are meaningless, and we’re back to square one. So let’s understand exactly how it works.
3. How RQVAE Works — The Engine Behind Semantic IDs
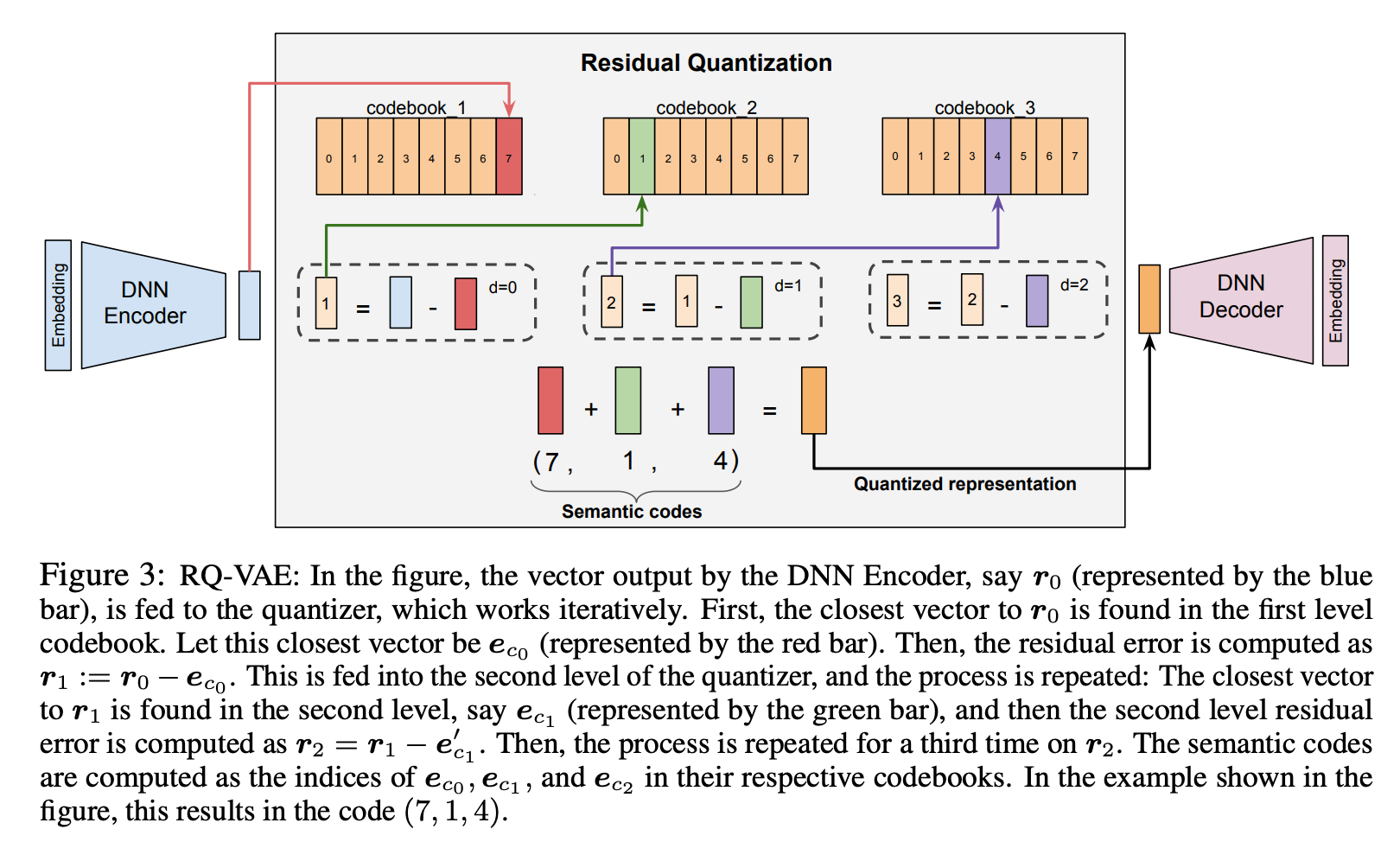
Residual Quantized VAE sounds intimidating, but the intuition is straightforward. It’s progressive compression — like describing a location with increasing precision.
“North America” tells you the continent. “California” narrows it down. “San Francisco” pins it to a city. Each level adds detail that the previous level didn’t capture. RQVAE does exactly this, but for item embeddings.
Here’s the algorithm.
Step 1: Encode. Take the 1024-dim item embedding and compress it through an encoder network (1024 → 512 → 256 → 128 → 32). It’s easier to follow with concrete numbers, so let’s walk through a simplified example — we will use 4 dimensions instead of 32, but the math is identical.
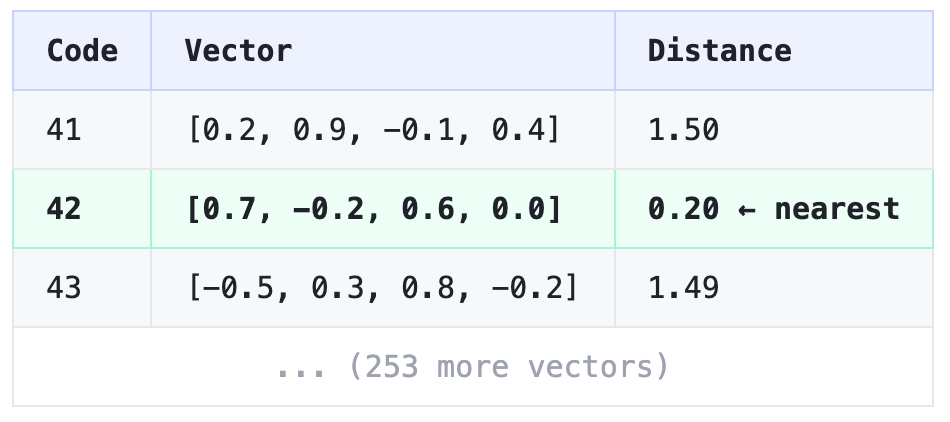
Encoded: [0.8, -0.3, 0.5, 0.1]Step 2: Level 1 Quantization. You have a codebook — a table of 256 learned vectors. Find the one closest to your latent vector: