
Library

Hey, Rahul here! 👋 Each week, I publish long-form ML+AI posts covering ML, AI, and System design for MLwhiz. Paid subscribers also get how-to guides with full code walkthroughs. I publish occasional extra articles. If you’d like to become a paid subscriber, here’s a button for that:

People ask me this all the time: “Where’s your post on LinkedIn?”
Most of the time, I am digging through my own archive on a phone and sending links one at a time. It’s not great. So I sat down, tagged every post I’ve written, organized them by theme, and put them all in one place. This is that page.
If you’re looking for something specific (your first ML job, learning PyTorch, building a recommender, shipping GenAI to production), start with the right category below.
The library is roughly organized as: a starter shelf, then series-driven deep dives, then thematic buckets for the standalone posts.
If you can’t find what you need, reply to any post and let me know. I’ll either point you to something or add it to the writing queue.
Jump to a section:
Start here
A handful of evergreen entry points. If you’re new to the blog, read these first.
RecSys for MLEs

The current series. From “how does a recommender actually work” to “how does Meta serve a trillion-parameter HSTU in production.” Each post stands alone, but they read best in order.
RecSys Fundamentals: The Art and Science of Digital Matchmaking
From Candidates to Clicks: The Engineering Anatomy of Ranking
Your Ranking Model Is Right. Your Recommendations Are Wrong (re-ranking)
From RNNs to Transformers: Building Sequential Recommenders (Part 9a)
From Random IDs to Semantic IDs: Building a Generative Recommender from Scratch (Part 9b)
HSTU: How Meta Built a Trillion-Parameter Recommender That Actually Scales (Part 9c)
Related: Vector Search at Scale: The Production Engineer’s Guide
GenAI, LLMs, and RAG
Everything LLM-shaped. The architectural journey, prompt engineering, fine-tuning, RAG (basic and agentic), production reality checks.
GenAI 101: How Generative AI is Rewriting the Rules for ML Engineers
A Review of the Architectural Journey of LLMs: Key Milestones from 2017 to Present
Everything you need to learn about GPT: How Does ChatGPT Work?
Everything Programmers need to learn about GPT: Using OpenAI
The Art and Science of Prompt Engineering: A Comprehensive Guide
Prompt Engineering: Why Your Tech Career Shouldn’t Rest on Vibes
Building Production-Grade Agentic RAG: Intelligent Recommendation Engines
Fine-Tuning LLMs: Your Guide to PEFT, QDoRA, and Other Nifty Tricks
What Production Deployments Taught Me About ReAct vs Function Calling
Did Apple Just Burst the AI Reasoning Bubble? I don’t think so
Transformers, BERT, and NLP

The NLP Learning Series is a complete 4-part walkthrough from preprocessing to transfer learning. Plus standalone deep dives on Transformers, BERT, and word embeddings.
NLP Learning Series (4 parts, text classification end to end):
Transformers and BERT:
Other NLP:
Using Deep Learning for End to End Multiclass Text Classification
Adding Interpretability to Multiclass Text Classification models
What my first Silver Medal taught me about Text Classification and Kaggle
Computer vision and Deep learning
Object detection, instance segmentation, GANs, image classification, and the PyTorch tooling that surrounds them.
Object detection and segmentation:
Demystifying Object Detection and Instance Segmentation for Data Scientists
Implementing Object Detection and Instance Segmentation for Data Scientists
How I Created a Dataset for Instance Segmentation from Scratch
GANs:
PyTorch and image classification:
Classical ML algorithms
The foundation. Feature work, evaluation, hyperparameter tuning, decision trees, XGBoost, time series, imbalanced data, interpretability.
The 5 Classification Evaluation metrics every Data Scientist must know
The 5 Feature Selection Algorithms every Data Scientist should know
Exploring Vowpal Wabbit with the Avazu Clickthrough Prediction Challenge
Statistics and probability
Distributions, p-values, confidence intervals, MCMC, and a few “your intuition is lying to you” pieces.
Python for ML engineer

Pandas, idioms, generators, decorators, async, dunders, regex, OOP. The Python-language layer of the job.
Idioms and patterns:
Concurrency and performance:
Visualization:
Pandas, Spark, and scaling data
Everything in the “make the data move faster” bucket. Pandas tricks, GPU pandas, PySpark from basics to production tips.
Pandas:
Spark and big data:
Graph algorithms on big data:
MLOps, deployment, and production
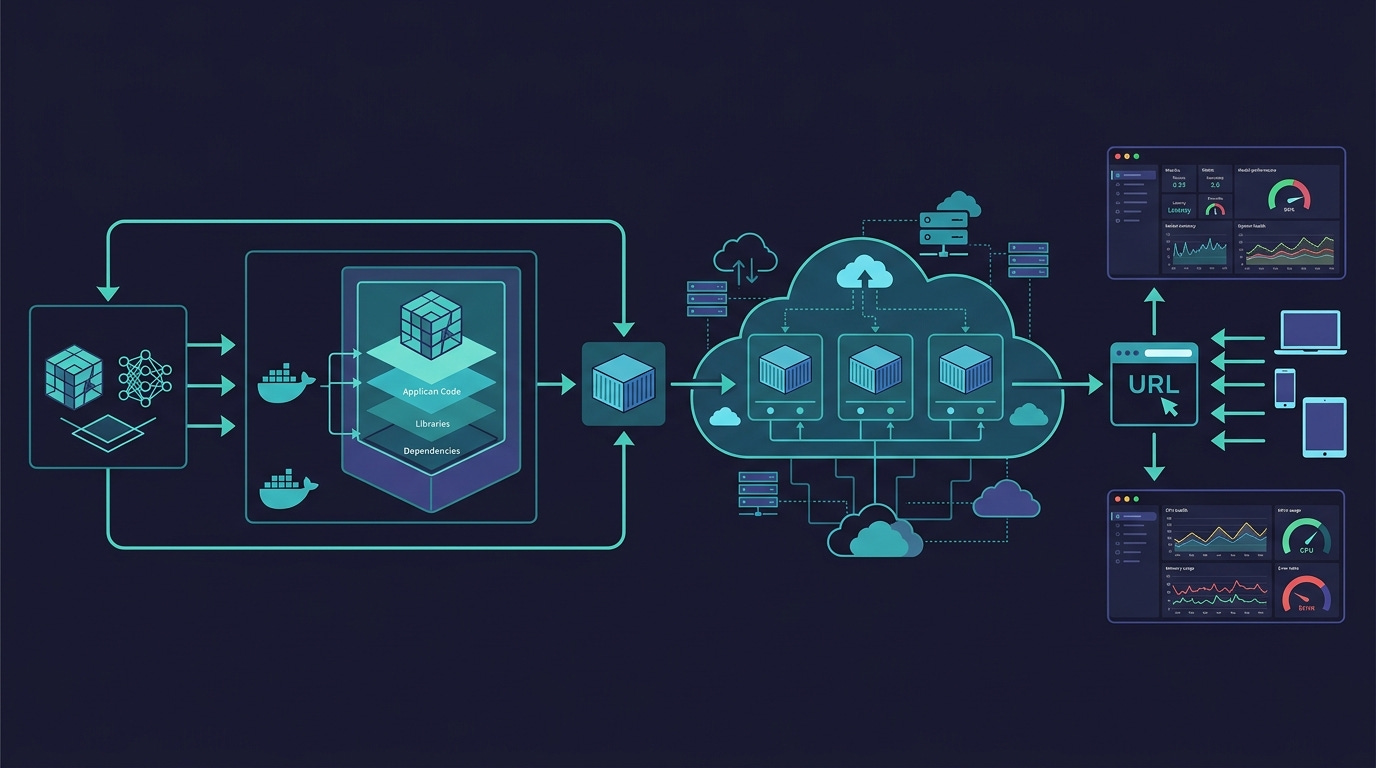
Flask, FastAPI, Streamlit, Docker, EC2. Taking a model from notebook to a URL someone else can hit.
Take your Machine Learning Models to Production with these 5 simple steps
How to write Web apps using simple Python for Data Scientists? (Streamlit intro)
How to Deploy a Streamlit App using an Amazon Free ec2 instance
Share your Projects even more easily with this New Streamlit Feature
A Layman’s Guide for Data Scientists to create APIs in minutes (FastAPI)
Deployment could be easy: A Data Scientist’s Guide to deploy an Image detection model
Coding interview algorithms
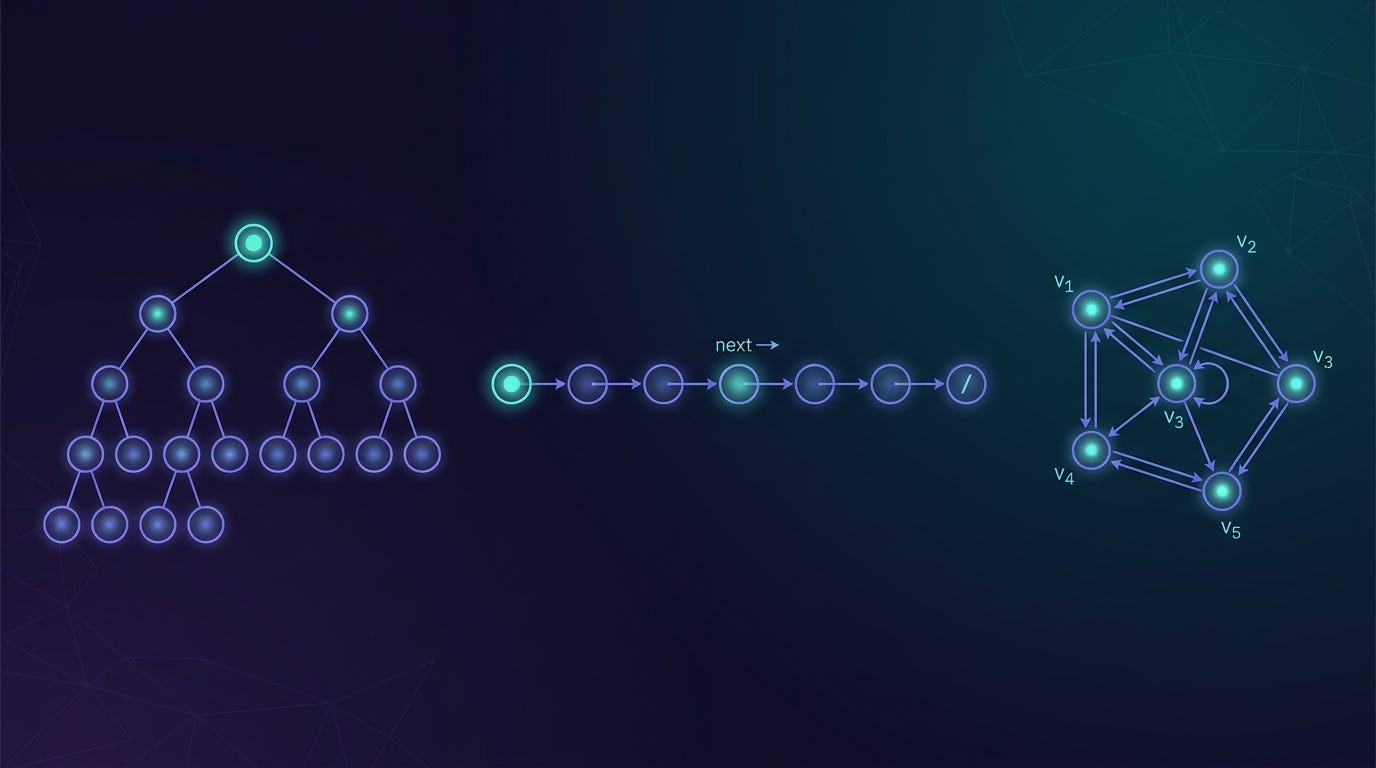
The patterns that come up in ML engineer interviews. Binary search, DP, linked lists, trees, graphs.
The one Graph Algorithm you need to know (connected components)
Career, interviews, and work

Interview prep, system design, and advice from someone who’s been on both sides of the hiring table.
Interview prep:
Career direction:
Become an ML Engineer with these courses from Amazon and Google
5 Essential Business-Oriented Critical Thinking Skills For Data Scientists
The Action-Planning Paradox: Balancing Execution and Strategy
Tools and setup

Workstations, IDEs, AI assistants, and dev environment.
AI assistants and Claude Code:
I Use Claude Code Every Day. Here’s the Setup That Actually Matters
Supercharge Your Claude: Adding Internet Powers with Brave Search
IDEs and editors:
Create an Awesome Development Setup for Data Science using Atom
Why Sublime Text for Data Science is Hotter than Jennifer Lawrence
Workstations and infra:
Stop Worrying and Create your Deep Learning Server in 30 minutes
A definitive guide for Setting up a Deep Learning Workstation with Ubuntu
Shell, SQL, and basics:
The MLWhiz Weekly newsletter
Curated AI/ML/RecSys/GenAI links each week. New issues every Sunday.
Asides and opinions
Off-topic essays, opinion pieces, and the occasional rant. Read these when you want a break from the technical posts.
Closing
That’s everything. ~160 posts across 12 years of writing.
If you got value from a specific post, share it with someone who’d benefit. If a topic is missing, reply to any of my posts and tell me what’s on your wish list. I read every reply.
If you want to support the work, the easiest way is to become a paid subscriber. Paid subscribers fund the deep-technical posts, which take real time to research, code, and illustrate.
Thanks for reading.